
전국 500만곳서 미세먼지 측정 추진
지역별 맞춤 저감 방안 수립 지원패션 유행 예측 등 소상공인에게 제공
버스 노선 등 대중교통 정책에도 활용
국제사회 데이터 공유 감염 확산 방지
KT 제공
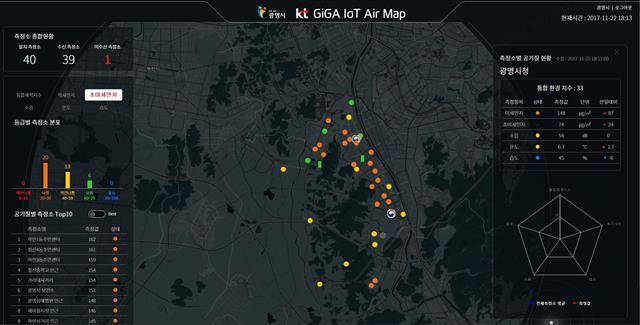
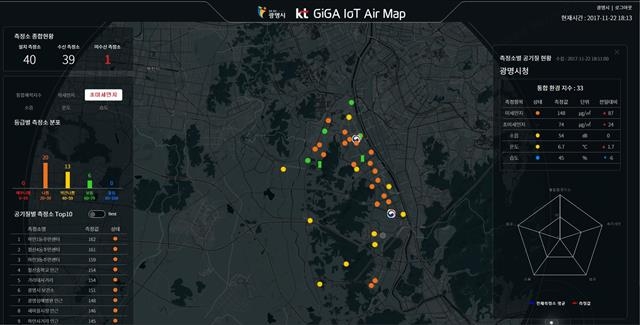
경기 광명시 곳곳에 설치된 KT ‘기가 사물인터넷 에어맵’으로 측정된 관측지점별 미세먼지 농도현황. 인근 지역임에도 미세먼지 나쁨(주황색), 약간 나쁨(노란색), 보통(초록색) 등의 신호가 섞여 있는 것을 볼 수 있다.
KT 제공
KT 제공
지난 22일 KT 미세먼지 분석원이 ‘기가 사물인터넷 에어맵’(GiGA IoT Air Map)의 실시간 미세먼지 관측화면을 보며 설명했다. 에어맵은 빅데이터 및 사물인터넷(IoT) 기술을 이용한 미래형 미세먼지 관측망이다. KT는 향후 100억원을 투자해 자사의 통신주 450만개, 기지국 3만 3000개, 전화부스 6만개 등 총 500만곳에 미세먼지 관측기를 부착하고, 여기서 나온 빅데이터를 분석해 정부에 전달할 계획이다.
현재 정부가 운영 중인 미세먼지 관측소는 300여개다. 한 관측소에서 측정하는 미세먼지 값이 반경 약 100㎞를 대표하기 때문에 정보를 세밀하게 제공하기는 힘들다. 실제 부산 동현초의 경우, 학교 밖에 있는 국가 관측망의 지난달 평균 미세먼지 농도(PM10)는 28.5㎍/㎥였지만 KT가 학교 내에 설치한 관측망의 측정 결과는 43.3㎍/㎥으로 1.5배 높았다.
KT는 10여개 권역에서 미세먼지 측정망을 가동한 결과, 장소마다 특화된 대처법이 필요하다고 전했다. 예를 들어 서울 수서 고속철도(SRT) 역사는 같은 건물임에도 지점마다 미세먼지 농도 차가 컸다. 상대적으로 환기가 잘되는 2번 출입구의 미세먼지 평균 측정값(11월 1~16일)은 68㎍/㎥이었지만, 승강장은 77㎍/㎥, 고객 라운지 80㎍/㎥, 매표소 82㎍/㎥ 등이었다. 이산화탄소의 양도 승강장은 559ppm이었지만 사람들이 많이 모이는 고객 라운지는 702ppm으로 25.6%나 차이 났다.
또 지난 22일 오후 6시 11분, 경기 광명도서관 실내의 미세먼지 농도는 불과 45㎍/㎥였지만 400m 떨어진 경기 광명사거리의 미세먼지 농도는 119㎍/㎥로 1.6배나 됐다.
KT 제공
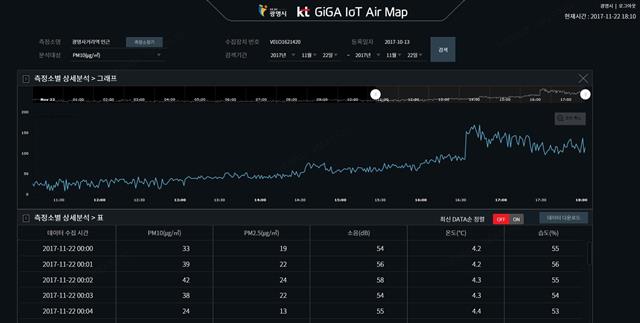
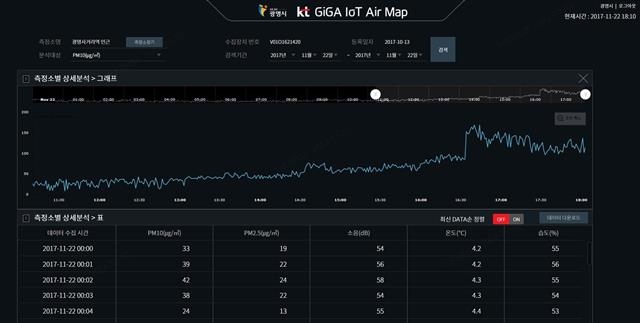
경기 광명시 곳곳에 설치된 KT ‘기가 사물인터넷 에어맵’이 관측한 지난 22일 시간별 농도현황.
KT 제공
KT 제공
현재 에어맵 시범실시 기관들은 빅데이터 분석 결과를 토대로 갖가지 미세먼지 절감 대책을 세우고 있다. 경기 양주 외식과학고는 실내 미세먼지 측정값에 따라 공기청정기를 가동하고, 광명시청은 미세먼지 농도가 짙은 곳을 중심으로 살수차 노선을 유동적으로 운영한다.
김형욱 KT 플랫폼사업기획실장은 “미래에는 미세먼지 빅데이터에 따라 자동으로 노선을 바꾸는 자율주행 살수차가 도입되고, 공조기의 세기를 조정하거나 창문이 자동으로 개폐되는 시스템을 구축하는 곳도 늘어날 것”이라고 예상했다.
빅데이터 기술을 활용한 기업들의 공공사업이 활기를 띠고 있다. 시민들에게 명절 교통 정보나 맛집, 인기 여행지 정보를 무료로 공개하는 것으로 시작된 ‘빅데이터 공공사업’은 정부에 감염병 추적 경로나 미세먼지 측정값을 알리거나 소상공인을 위해 최신 트렌드 정보를 공개하는 식으로 확대되고 있다. 기업들이 막대한 자금을 들여 개발한 기술을 앞다투어 무료로 내놓는 데는 기업의 사회적 책임을 다하겠다는 취지도 있지만, 4차 산업혁명의 기반인 빅데이터 기술 경쟁에서 우위를 점하겠다는 목표도 있다.
KT의 ‘감염병 확산 방지 프로젝트’도 G20에서 나라별 감염병 데이터의 공유를 논의하면서 널리 알려지게 된 빅데이터 공공사업이다. 통신사가 로밍 데이터를 분석해 감염병 우려국에 다녀온 시민을 파악하고 질병관리본부에 전달한다. 또 해당 시민에게는 ‘감염병 예방 및 신고요령’을 문자로 보내는 식이다. KT가 지난해 11월 처음 시작했고, 현재 각국 확산을 위해 케냐, 아랍에미리트 등의 정부 및 통신사와 협의 중이다.
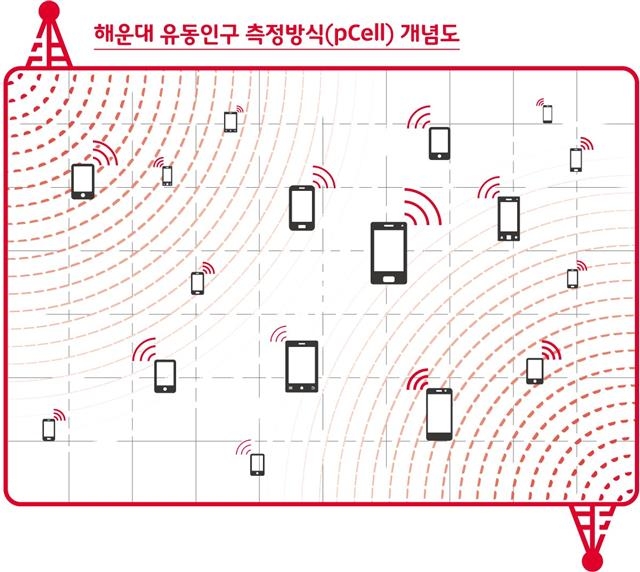
SK텔레콤 제공
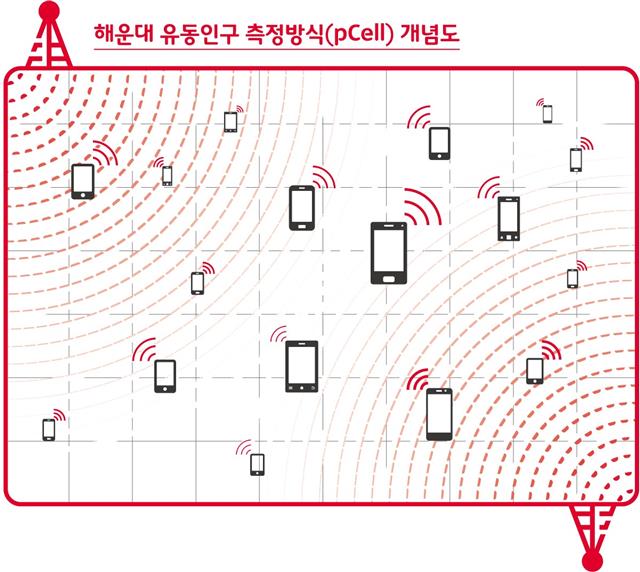
SK텔레콤의 유동인구 측정방식 개념도. 기지국 신호의 세기를 계산해 일정지역 안에 있는 휴대전화 개수를 파악하고, 이 정보를 가공해 인파의 수를 알아낸다.
SK텔레콤 제공
SK텔레콤 제공
SK텔레콤은 빅데이터 기술로 한 장소에 모인 인파를 산정하는 방식을 고안해 공공기관에 제공 중이다. 현재 주로 쓰이는 페르미 방식은 단위 면적에 있는 사람의 수를 세고서 면적을 곱하는 방식이어서 오류 가능성이 큰 편이다. 실제 지난해 말 촛불집회 때 페르미법을 쓰는 경찰의 추산 인원과 집회 주최 측의 추산치가 10배까지 차이 나면서 논란이 되기도 했다.
SK텔레콤은 각 이동통신 기지국의 신호세기를 계산해 기지국이 미치는 범위 내에 있는 스마트폰의 개수를 파악한다. 30분 이상 체류한 단말기 수를 조사한 뒤 통신사 시장점유율, 전원을 끈 비율, 휴대전화 미소지자 비율 등을 적용해 인파를 세는 식이다. 시간별 유동인구나 일정 구획별로 인파를 세밀하게 측정할 수 있기 때문에 교통 대책을 세우거나 재해·재난 대응책 마련에 기초 자료로 쓰인다.
교통수단이 없는 외딴 지역과 산업단지·관광지를 오가는 경기도의 ‘따복버스’(따뜻한 복지버스)도 SK텔레콤의 빅데이터 분석을 통해 확산했다. 운송업체들이 불규칙한 수요로 정규 노선 편성을 기피했지만 이용자 동선을 분석하고 ‘출퇴근형’, ‘관광형’ 등 특화된 노선을 구축하면서 성공을 거둔 사례다.
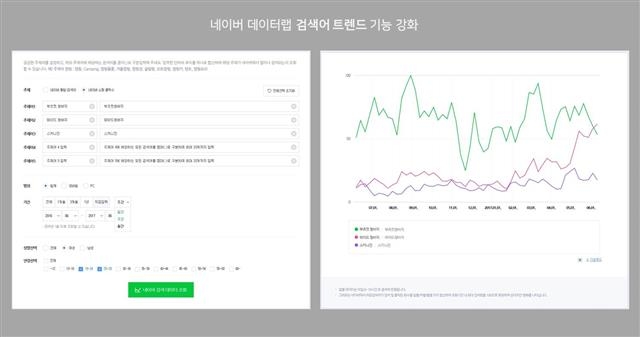
네이버 제공
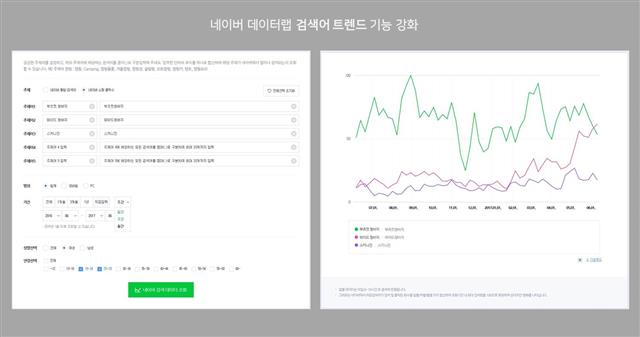
네이버의 빅데이터 플랫폼 ‘데이터랩’의 검색 화면. ‘부츠컷 청바지’, ‘와이드 청바지’, ‘스키니진’ 중 20대 여성들이 어떤 패션을 가장 많이 검색했는지를 보여 주고 있다.
네이버 제공
네이버 제공
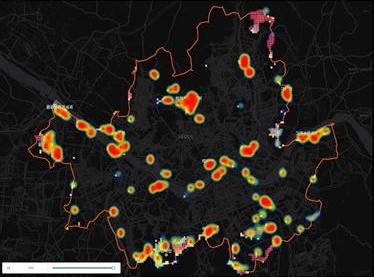
카카오택시 제공
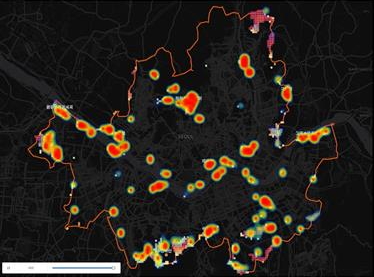
서울 시내 대중교통 불편 지역에서 이뤄진 카카오택시 호출 현황.
카카오택시 제공
카카오택시 제공
●“공공성 빅데이터 공개 범위 논의해야”
기업들이 공공의 이익을 위해 빅데이터 분석기술을 제공하는 데는 미래 산업 경쟁에서 앞서가려는 포석도 있다. 빅데이터는 인공지능(AI), 사물인터넷, 로봇, 자율주행차 등 수 많은 4차 산업혁명 기술의 기반이 된다. AI 스피커는 각국의 언어와 방언에 대한 대화 데이터가 많을수록 명령을 잘 알아듣고 자율주행차는 도로, 지형, 표지판뿐 아니라 운전자의 습관까지 데이터로 분석했을 때 안정성이 높아진다.
시장조사업체 IDC은 지난해 16ZB(1ZB=10해 바이트)를 넘어선 전 세계 데이터량이 2025년 163ZB를 기록하면서 10배 이상으로 급증할 것으로 예측했다. 특히 한 사람이 생산하는 하루 평균 데이터 생성 건수는 2015년 218건에서 2025년 4785건까지 22배로 늘어날 전망이다.
차두원 한국과학기술기획평가원 연구위원은 “어떤 미래 기술이 소비자의 선택을 받게 될지 모르는 불확실한 상황에서 빅데이터를 보유한 기업의 경우 선택받은 미래 기술을 상용화시키는 기간을 크게 줄일 수 있다”며 “시민에게 이익을 주고 빅데이터도 수집할 수 있는 공공영역의 빅데이터 사업은 향후 더 활발해질 것”이라고 말했다. 김학래 한국과학기술연구정보원 박사는 “도로, 미세먼지, 교통량, 국립공원, 날씨 등 기업들이 소비자에게 제공하는 빅데이터의 대부분은 그 원천이 공공정보”라며 “따라서 공공정보를 가공한 기업들의 빅데이터를 어느 정도까지 사회에 공개토록 할지, 사회적 논의도 필요하다”고 전했다.
이경주 기자 kdlrudwn@seoul.co.kr
2017-11-25 14면
Copyright ⓒ 서울신문. All rights reserved. 무단 전재-재배포, AI 학습 및 활용 금지




































